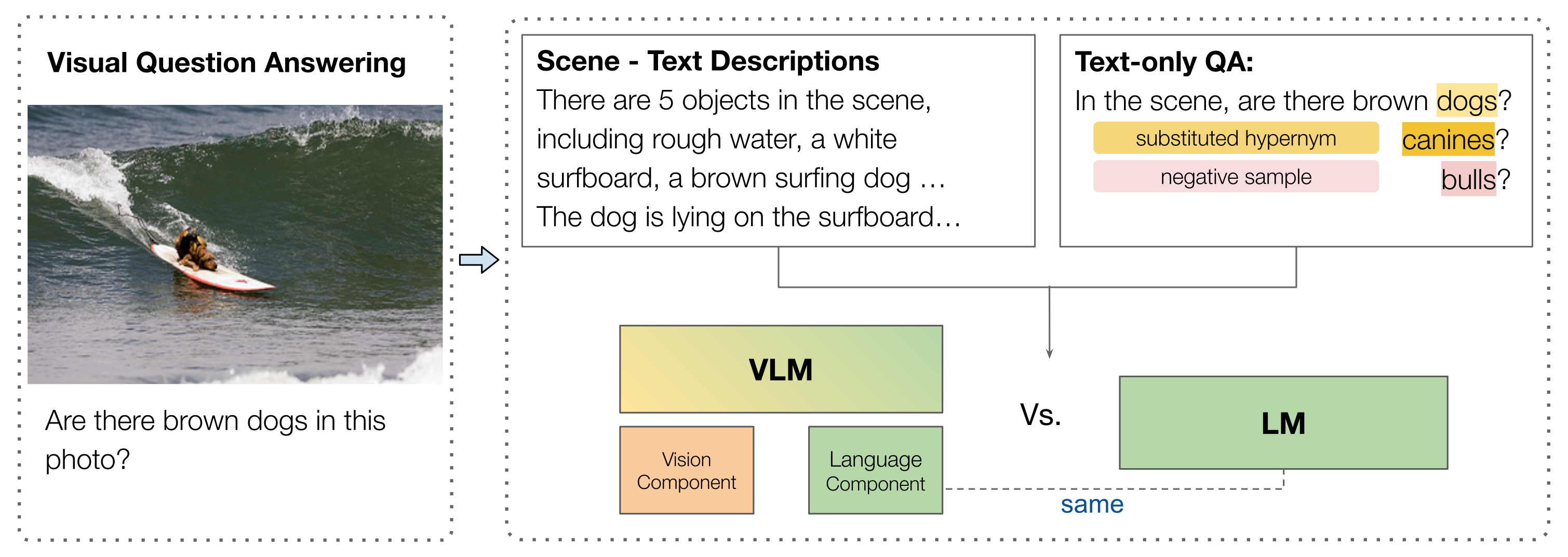
Does vision-and-language (VL) training change the linguistic representations of language models in meaningful ways? Most results in the literature have shown inconsistent or marginal differences, both behaviorally and representationally. In this work, we start from the hypothesis that the domain in which VL training could have a significant effect is lexical-conceptual knowledge, in particular its taxonomic organization. Through comparing minimal pairs of text-only LMs and their VL-trained counterparts, we first show that the VL models often outperform their text-only counterparts on a text-only question-answering task that requires taxonomic understanding of concepts mentioned in the questions. Using an array of targeted behavioral and representational analyses, we show that the LMs and VLMs do not differ significantly in terms of their taxonomic knowledge itself, but they differ in how they represent questions that contain concepts in a taxonomic relation vs. a non-taxonomic relation. This implies that the taxonomic knowledge itself does not change substantially through additional VL training, but VL training does improve the deployment of this knowledge in the context of a specific task, even when the presentation of the task is purely linguistic.
We investigate how vision-and-language training impacts the taxonomic knowledge of language models. To this end, we make the following contributions:
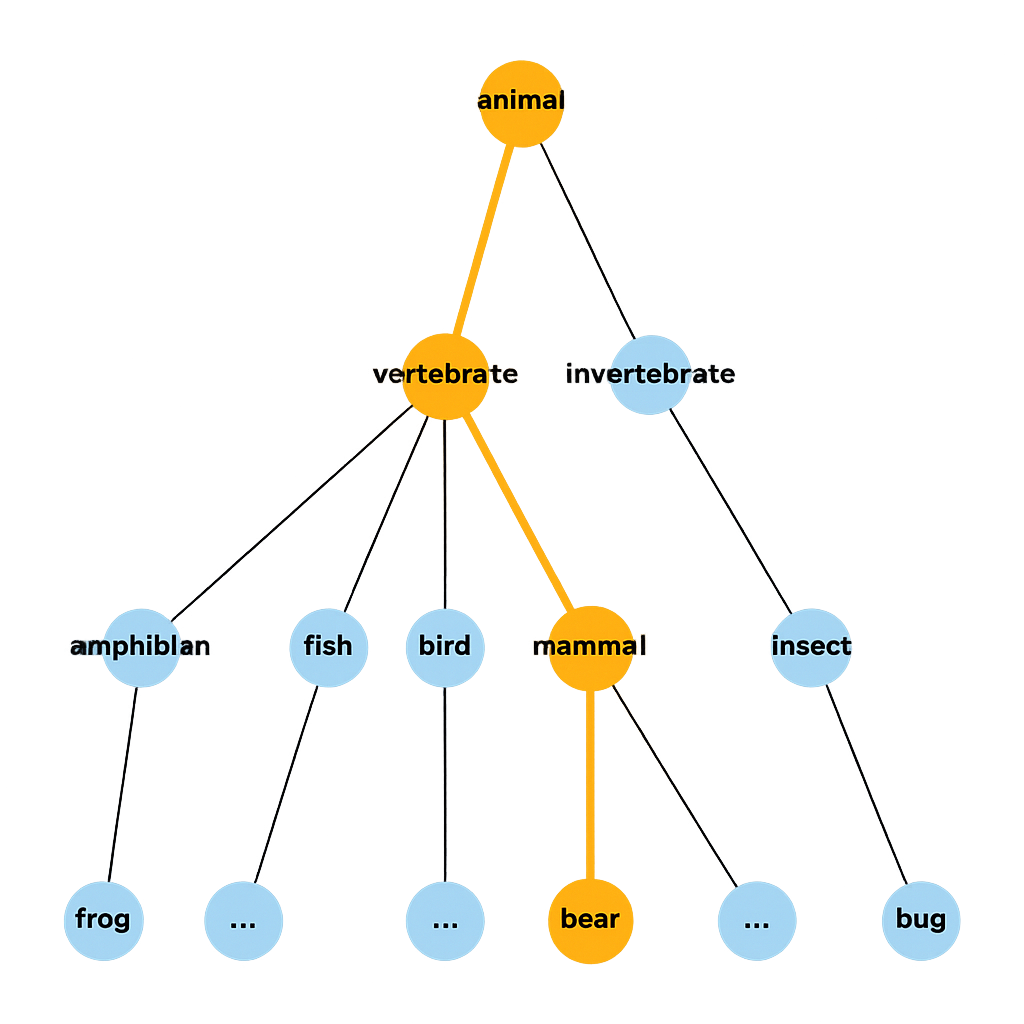
We apply a three-step transformation to GQA to create TaxonomiGQA:
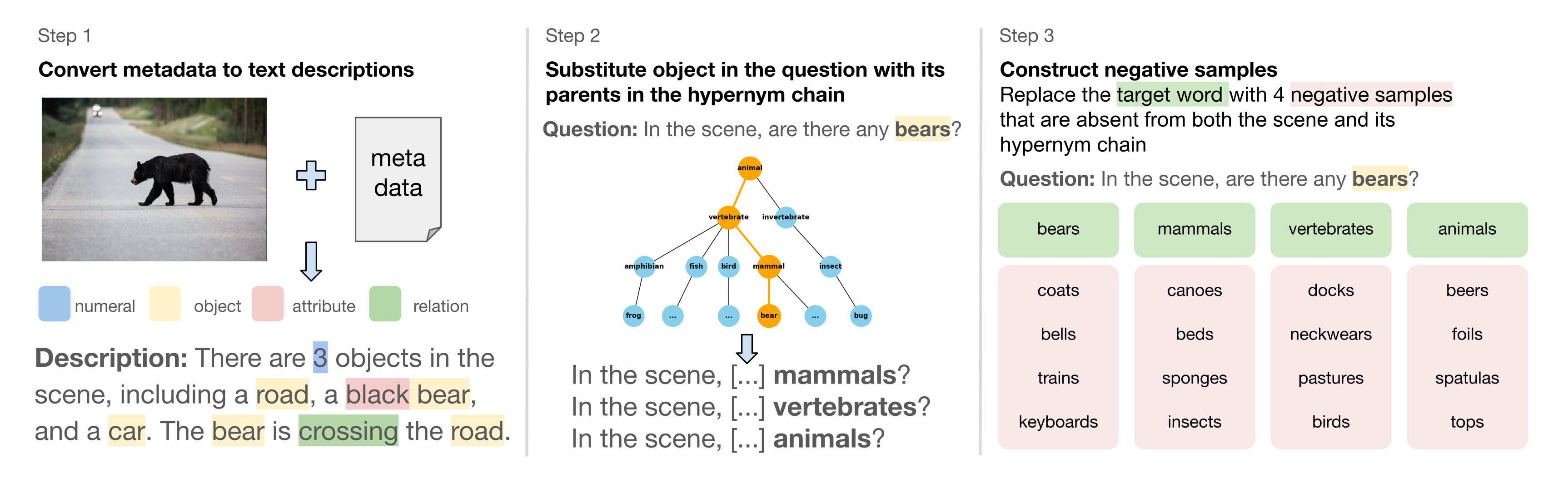
Our three-step pipeline for generating the TaxonomiGQA dataset.
More details on question filtering and negative sampling can be found in Appendix C of the paper.
We evaluated 7 minimal pairs of LMs and their VLM counterparts, where each pair shares the same base language model.
VLMs achieved higher scores than LMs on all three evaluation metrics: Overall Accuracy, Conditional Accuracy, and Hierarchical Consistency. This held across nearly all model pairs (with the exception of Vicuna vs. Llava-1.5), showing that VL training yield improvements in _text-only_ QA that requires sensitivity to taxonomic knowledge.
Performance of VLM-LM model pairs on TaxonomiGQA and TAXOMPS. Points above the diagonal indicate cases where the VLM outperforms the LM.
To explain these observations, we put forth two hypotheses:
To test whether VL training alters the underlying taxonomic knowledge itself, we introduced TAXOMPS (taxonomic minimal pairs), a QA dataset constructed on top of our taxonomy, which directly asks whether one concept is a kind of another (e.g., “Is a cat an animal?”) along with four minimal pair questions (e.g., "Is a cat a vegetable?"). Both LMs and VLMs performed similarly well, indicating that their underlying taxonomic knowledge remains largely unchanged by VL training.
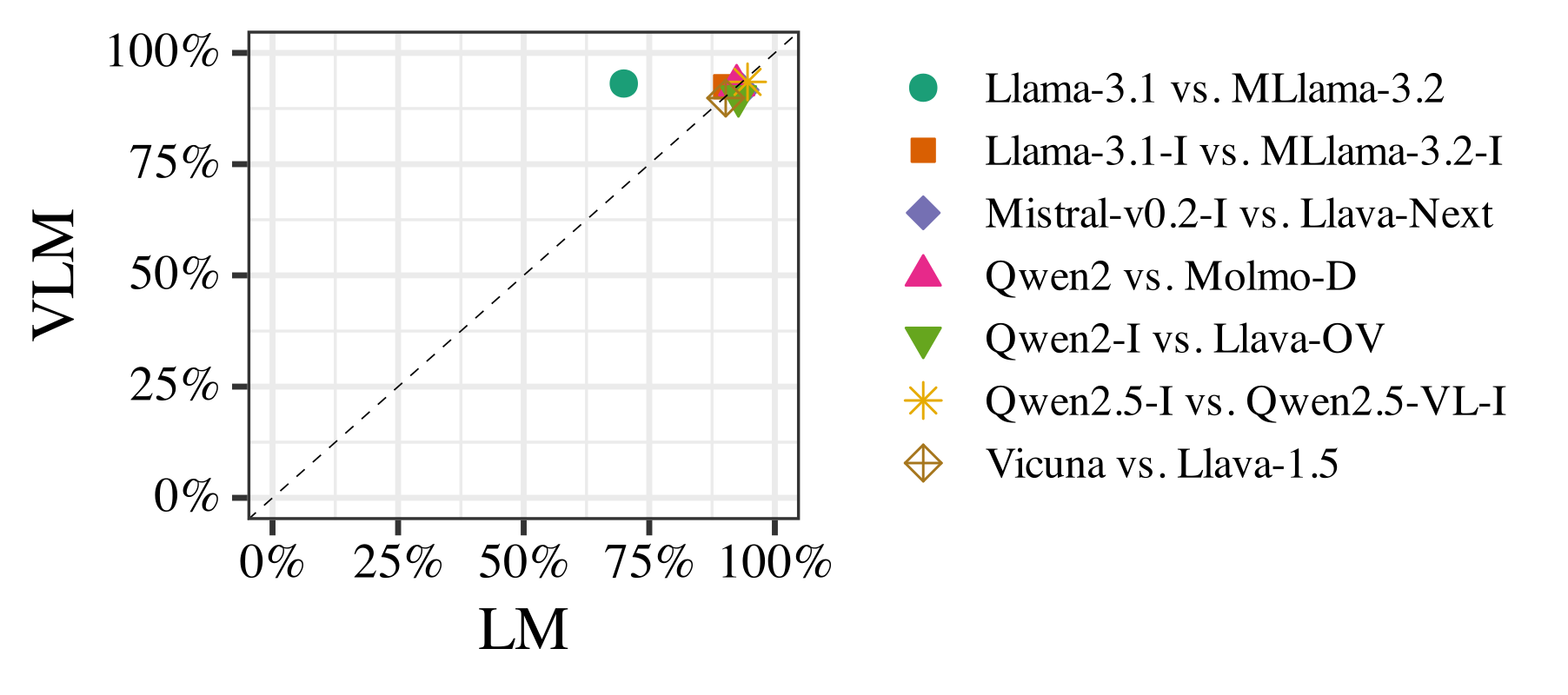
Performance on TAXOMPS. Most model pairs perform similarly well, with points clustered on the diagonal.
We further confirmed this through Representational Similarity Analysis (RSA) on top of hierarchically sensitive representations extracted from the LM and the VLM (using the method developed by Park et al., 2024). We found no significant difference between these representations in any LM-VLM pair.
While their underlying knowledge was found to be similar to that of LMs, VLMs show a clear advantage in how they deploy that knowledge in task contexts. Two key analyses performed on the Qwen 2.5 pair (most salient differences in TaxonomiGQA performance) support this:
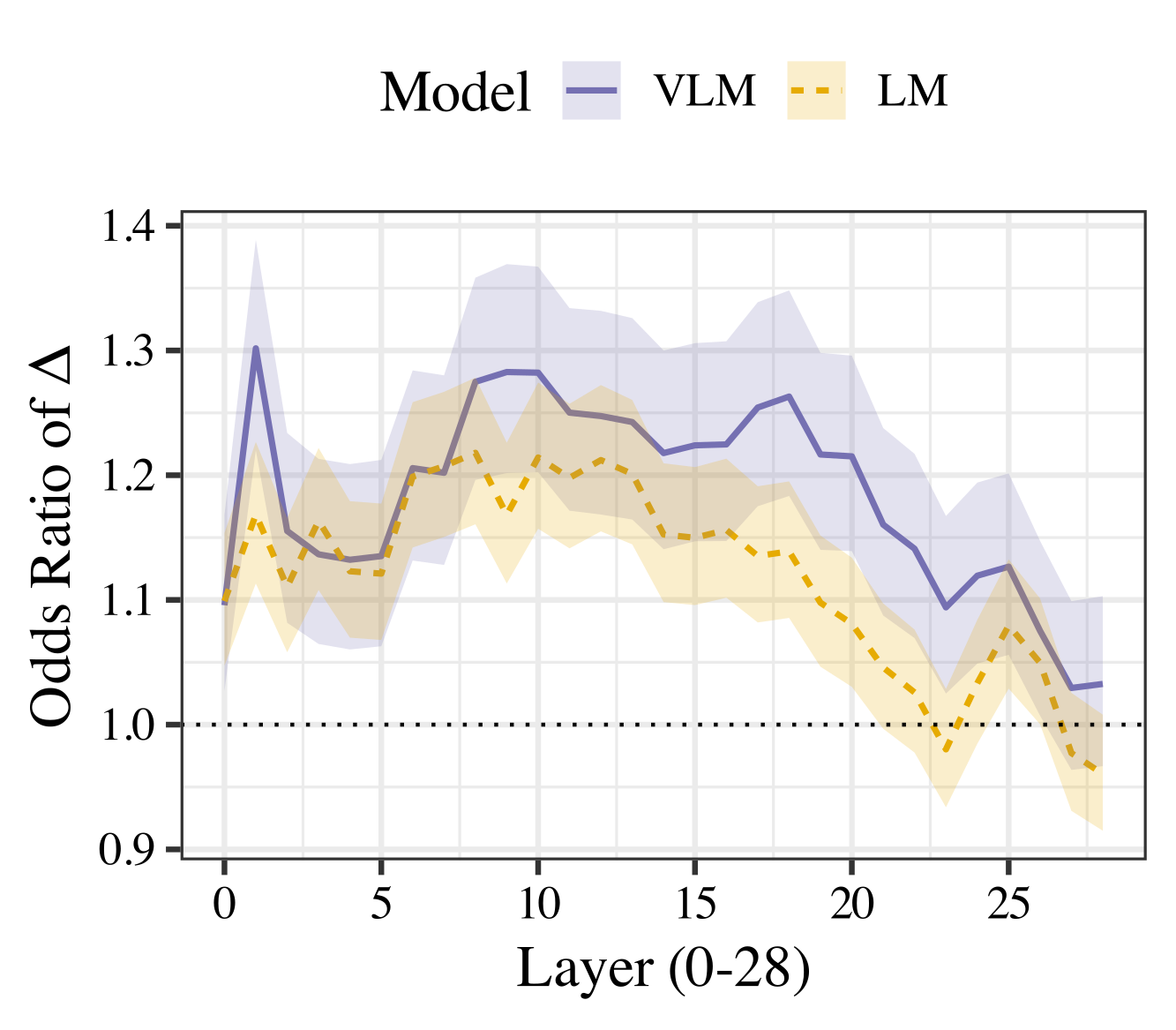
Odds ratios from logistic regression: contextualized similarity is associated with accuracy more strongly in Qwen2.5-VL than its base LM.
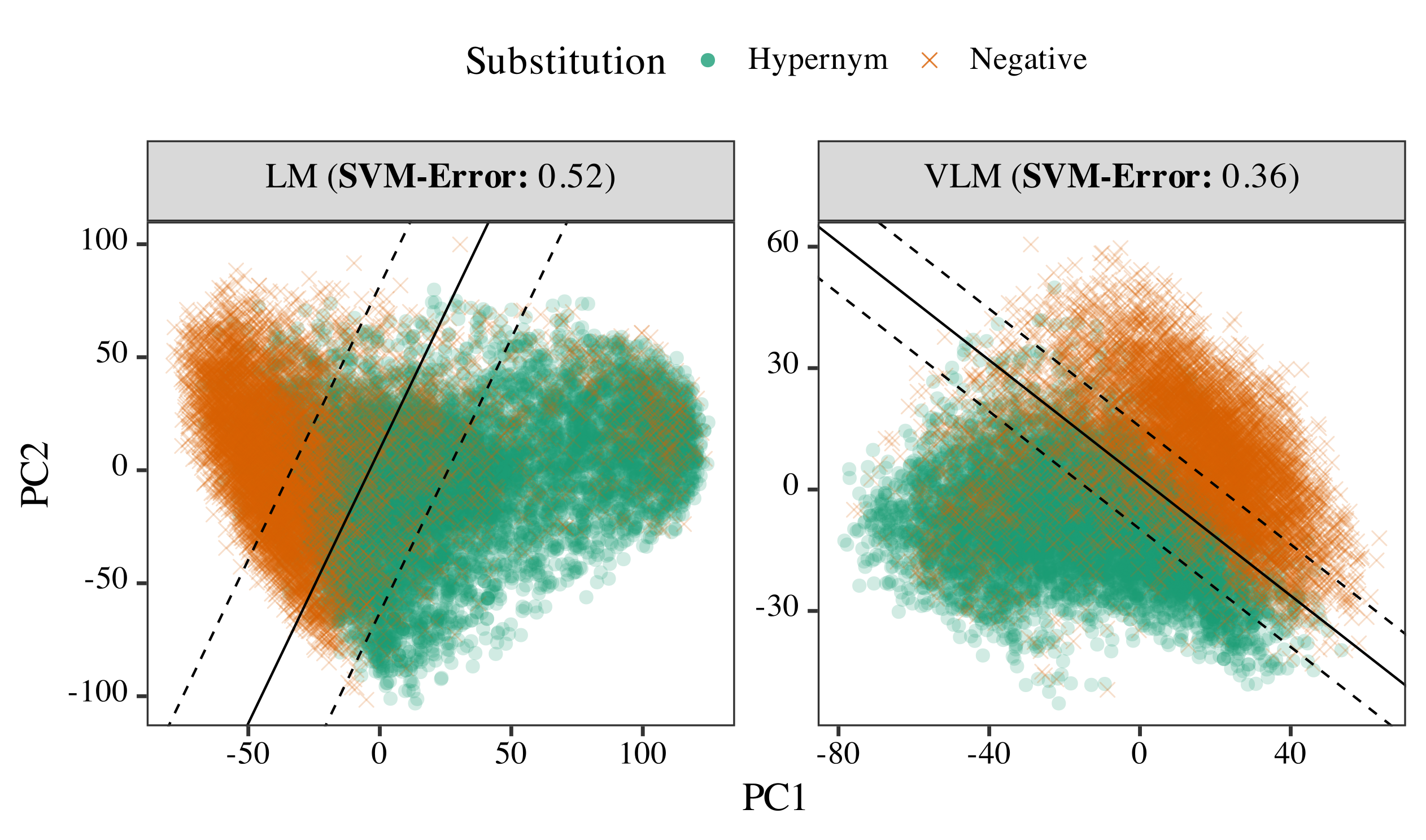
Contextualized representational analysis on Qwen2.5-I (LM) and Qwen2.5-VL-I (VLM).
To understand why VL training improves taxonomic reasoning in text-only settings, we explored whether visual similarity between related concepts helps models apply their knowledge more effectively.
b = 0.52, SE = 0.19, p < .01). No such effect was found for LMs (b = 0.23, SE = 0.17, p = 0.18).
Effect of visual similarity on VLM performance across concepts. Bar color reflects visual cohesion (darker = higher cohesion).
These results suggest that VL training may help models exploit visual regularities in concept hierarchies, especially when categories have largely similar visual features.
By developing TaxonomiGQA, a QA dataset that requires sensitivity to taxonomic knowledge, we showed that VLMs outperformed their LM counterparts across all metrics despite TaxonomiGQA being a purely text-based dataset. We furthermore show that vision-and-language training doesn’t fundamentally change a model’s taxonomic knowledge. Instead, it improves how models apply that knowledge when solving tasks.
Through a series of behavioral and representational analyses, we find that VLMs form stronger contextual links between related concepts and represent taxonomic distinctions more distinctly in downstream tasks. This advantage appears linked to the visual similarity and cohesion among concepts in the taxonomic hierarchy.
Looking ahead: our analyses are correlational in nature. A key direction for future work is establishing causal links between VL training and task-specific deployment behavior, potentially by analyzing training data, probing internal objectives, or manipulating visual features during pretraining. There is also room to explore whether VLMs encode non-linear taxonomic distinctions that aren’t captured by the linear separability analyses used here.
@article{qin2025vision,
title={Vision-and-Language Training Helps Deploy Taxonomic Knowledge but Does Not Fundamentally Alter It},
author={Qin, Yulu and Varghese, Dheeraj and Lindstr{\"o}m, Adam Dahlgren and Donatelli, Lucia and Misra, Kanishka and Kim, Najoung},
journal={arXiv preprint arXiv:2507.13328},
year={2025}
}